This post summarises the key findings from my MSc Cybersecurity dissertation, completed at Wrexham University in April 2026. The full testbed code is on GitHub.
Background
ModSecurity is one of the most widely deployed open-source Web Application Firewalls. When paired with the OWASP Core Rule Set (CRS), it gives you a structured ruleset for detecting SQL injection, cross-site scripting, path traversal, and more.
The CRS uses an anomaly scoring model. Rules don't block requests directly. They contribute severity scores to a running total, and a separate blocking rule (949110) fires only when that cumulative score meets or exceeds a configured inbound anomaly threshold. This architecture is important for understanding what paranoia levels actually do.
Paranoia levels (PL1–PL4) control two things simultaneously: which rules are loaded, and what the blocking threshold is. PL1 is the default, with a threshold of 5. PL2 loads additional rules and drops the threshold to 3. PL3 and PL4 go further still. The implicit assumption in the documentation is that each step up improves detection coverage, at the cost of more false positives.
But does raising from PL1 to PL2 actually catch more attacks?
What I Tested
- WAF: ModSecurity v3.0.14 with NGINX, using the official
owasp/modsecurity-crs:nginxDocker image - Ruleset: OWASP CRS 3.3.8
- Target application: OWASP Juice Shop, in a separate container behind the WAF
- Configurations: PL1 (inbound threshold T=5) and PL2 (inbound threshold T=3)
- Dataset: 200 malicious payloads (100 SQLi, 100 XSS) and 500 deliberately constructed benign requests
- Environment: Fully containerised via Docker Compose on a Windows 11 workstation with WSL2
The two configurations differed only in paranoia level and threshold. All other parameters were identical, including the target, the payload set, and the execution environment.
The Dataset
Malicious payloads (200 total) were split equally across five subcategories for each attack type:
- SQLi: Basic, Boolean, Union, Time-Based, Obfuscated
- XSS: Basic, Event-Based, Mixed-Evasion, Obfuscated, Advanced
All payloads came from publicly documented sources: PayloadsAllTheThings, the OWASP Web Security Testing Guide, the PortSwigger XSS Cheat Sheet, the CRS regression test suite, and OWASP XSS Filter Evasion documentation.
Benign requests (500 total) were deliberately designed to stress WAF false positive behaviour, spread across four subcategories: SQL-Keyword (innocent search strings that happen to contain SQL words like SELECT or INNER JOIN), Scripting-Keyword (strings containing words like eval or exec in natural English), Special-Chars (e-commerce strings with percentage characters like "100% natural"), and Neutral (clean product descriptions).
Results
| Metric | PL1 | PL2 |
|---|---|---|
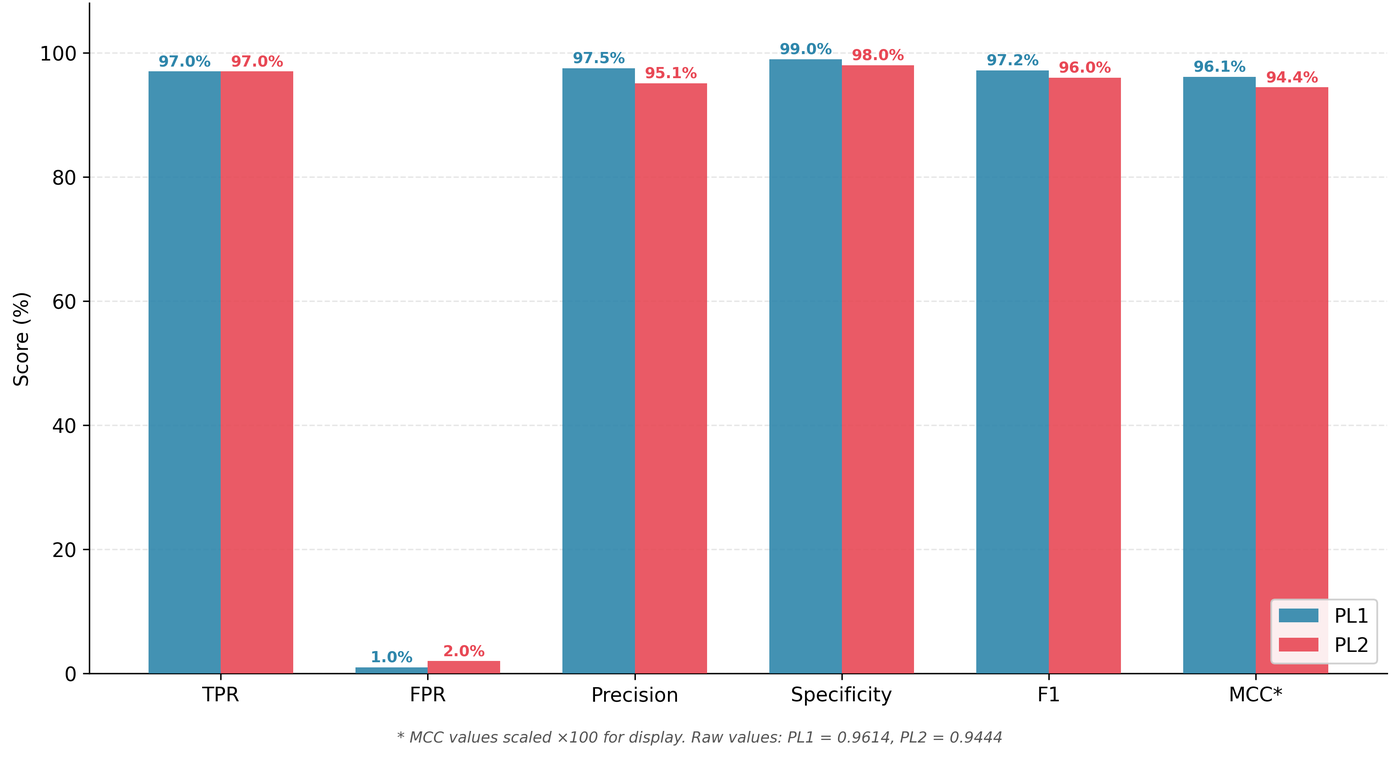
| True Positive Rate (TPR) | 97.0% | 97.0% |
| False Positive Rate (FPR) | 1.0% | 2.0% |
| Precision | 97.5% | 95.1% |
| Specificity | 99.0% | 98.0% |
| F1 Score | 97.2% | 96.0% |
| Matthews Correlation Coefficient | 0.9614 | 0.9444 |
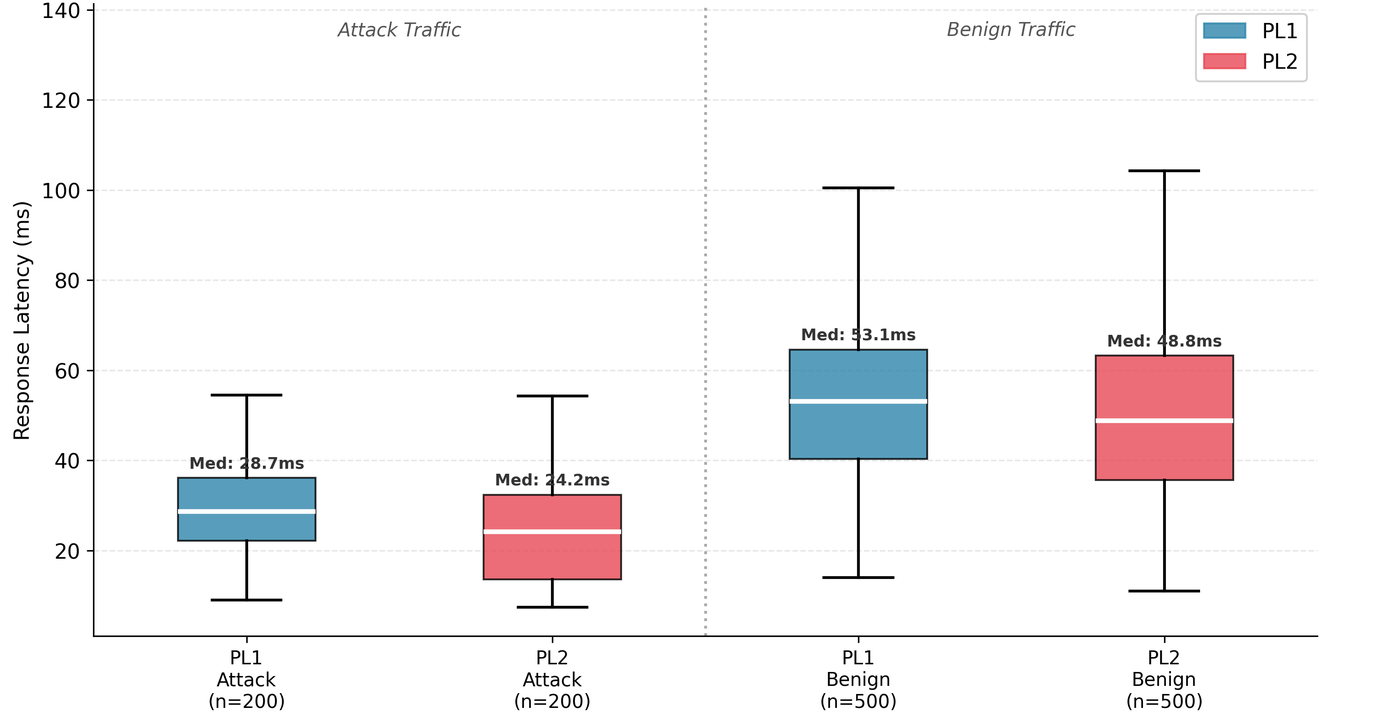
| Mean Latency | 46.66ms | 41.93ms |
The headline: identical detection, measurable false positive cost, and no latency penalty.
The Central Finding: No PL2 Rules Fired
This is the mechanistic core of the dissertation, and it's more precise than just saying "TPR was the same."
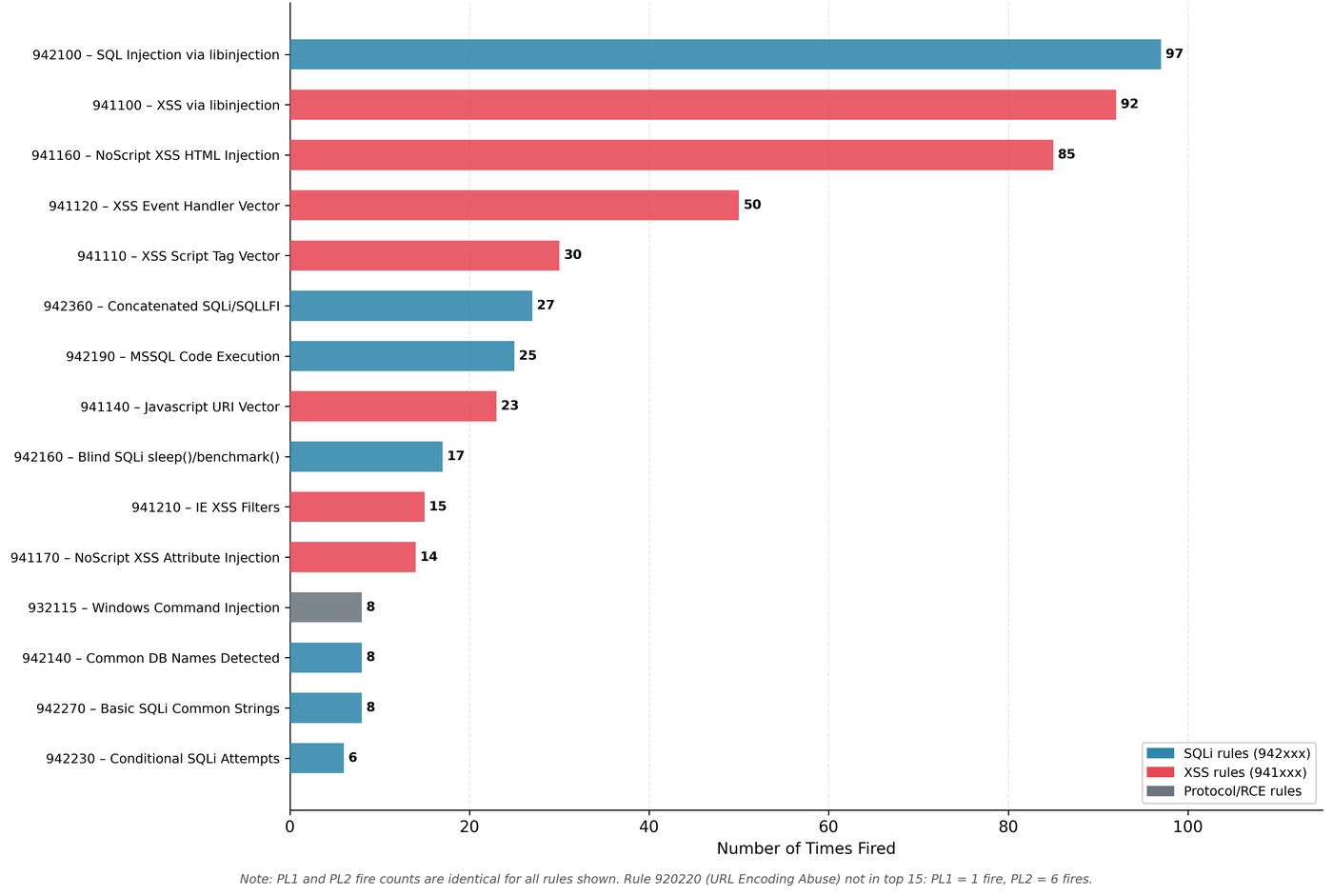
Across both configurations, 37 unique CRS rules fired. Every single one of them carried the paranoia-level/1 tag. No rule tagged paranoia-level/2, /3, or /4 fired in either the PL1 or the PL2 run.
This has a direct consequence for how you interpret the results. The CRS blocking condition is:
Block the request if cumulative anomaly score S ≥ threshold T
If identical rules fire in both configurations, S is identical for every request. The 194 malicious requests that were detected had scores comfortably exceeding both thresholds (minimum malicious score was 5, which meets both T=5 and T=3). The six bypasses had S=0: no rules fired at all, so no threshold could have caught them regardless of its value.
PL2 loaded additional rules. Those rules were evaluated against every request. They simply never matched anything in this payload set.
The implication: the only operative difference between PL1 and PL2 in this experiment was the value of T. Rule expansion did not contribute. This is the threshold-not-rules mechanism, and it directly explains why every metric that incorporates TPR shows no change, while every metric that incorporates FPR gets worse under PL2.
Where Detection Failed: The Six Bypasses
Six payloads evaded both configurations. They are worth examining individually because they fall into three distinct categories.
Comment manipulation (2 payloads):
- admin'#: the MySQL hash character # terminates SQL queries just like --, but CRS rule 942270 only covers double-dash and C-style comment syntax. No equivalent signature exists for the hash terminator.
- ' UN/**/ION SEL/**/ECT 1,2--: inserting empty comments mid-keyword breaks the UNION and SELECT pattern matching. Compare this to ' /*!UNION*/ /*!SELECT*/ 1,2--, which uses MySQL version-specific comment syntax and was blocked at score 10 by two rules. Same underlying attack, different obfuscation, different outcome.
Structural gaps (2 payloads):
- Both used CASE WHEN conditional constructs (1 AND (SELECT CASE WHEN (1=1) THEN 1 ELSE 0 END)=1). Rule 942230 targets conditional SQLi but doesn't match this specific syntax. Libinjection (the heuristic engine behind rule 942100) also failed to classify these as injection.
Double URL encoding (2 payloads, one SQLi, one XSS): - Both exploited the WAF's single decode pass. After one decoding round, the payload still appears percent-encoded and doesn't match any detection signature. The actual injection is only visible after a second decode at the application layer. This is a documented OWASP technique, and it works at both paranoia levels because it's a pre-processing limitation, not a detection sensitivity issue. No threshold reduction can close this gap.
All six bypasses produced HTTP 500 or HTTP 200 responses from the backend, confirming genuine application-layer reach.
False Positives: Rule 920220 and the Percentage Problem
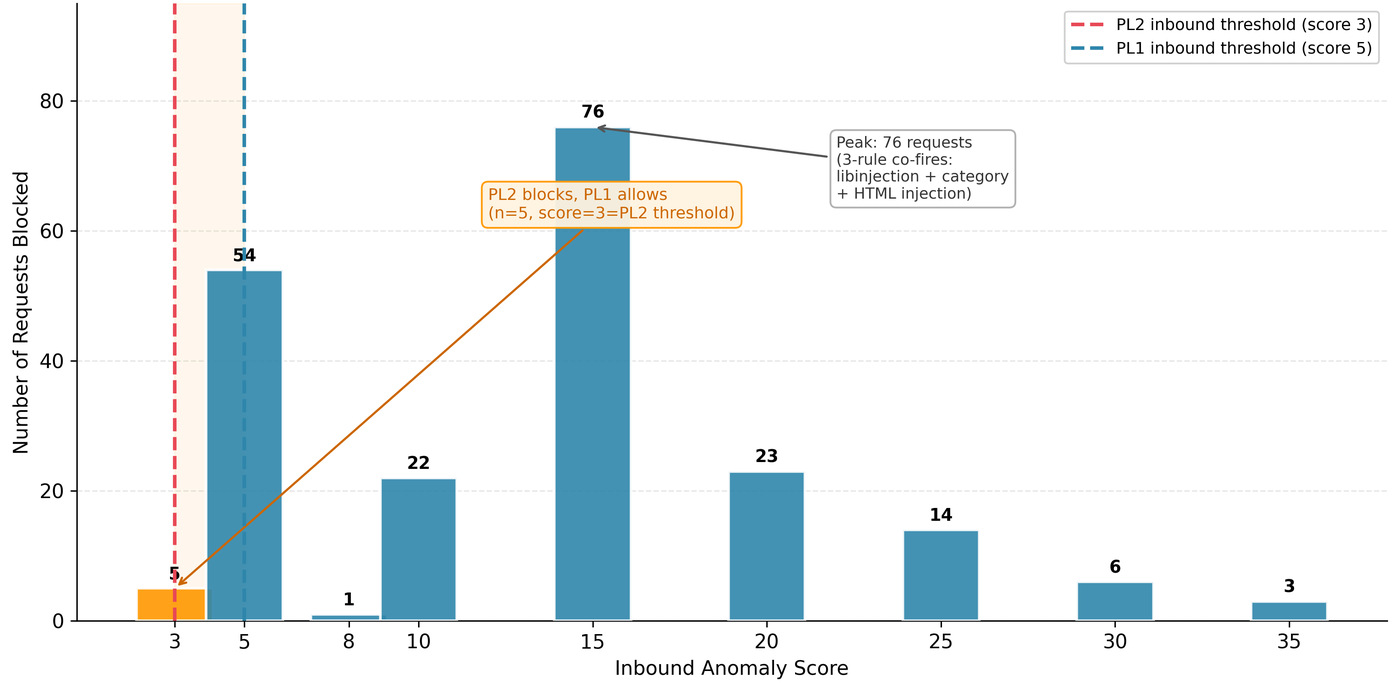
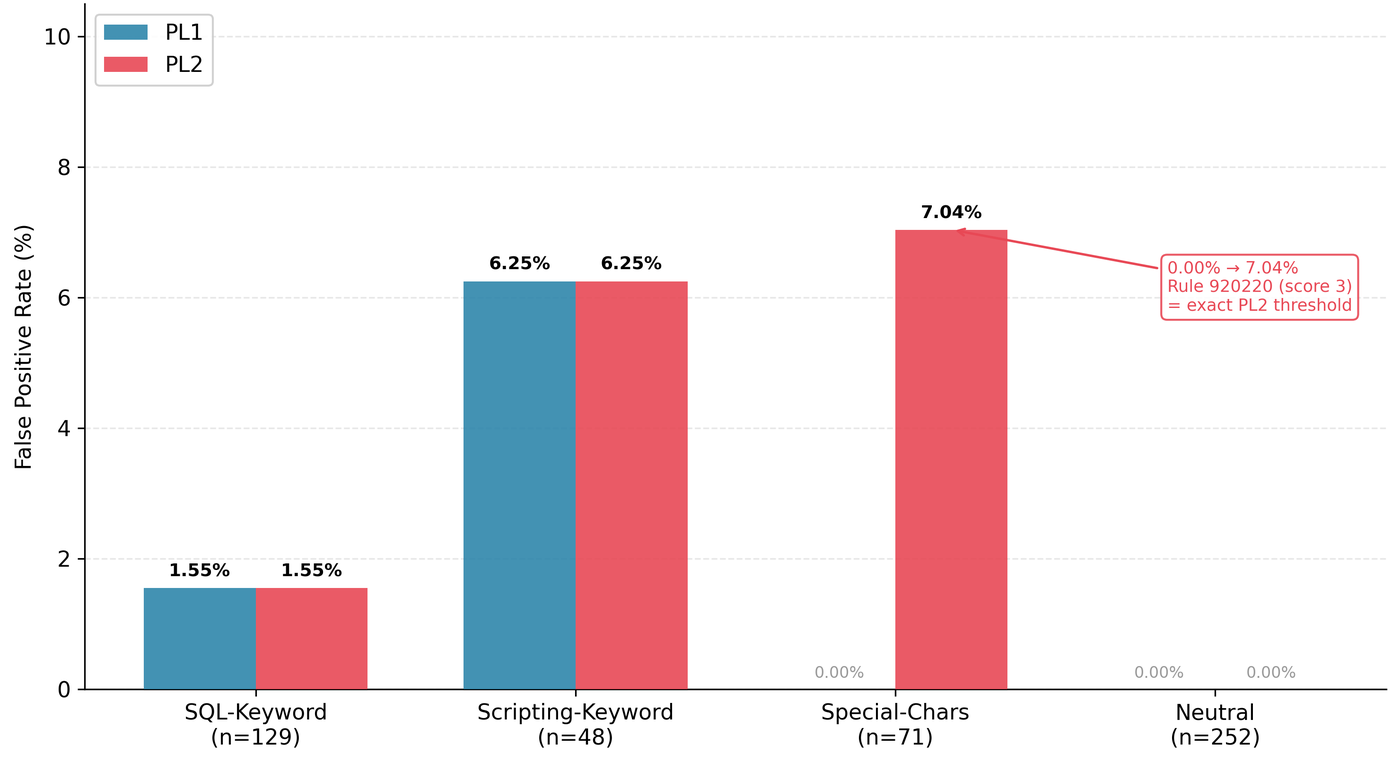
PL1 produced five false positives (FPR 1.0%). PL2 produced ten (FPR 2.0%). The five additional false positives under PL2 were all caused by the same rule: rule 920220 (URL Encoding Abuse Attack Attempt), which fires on percentage characters in the request.
Benign strings like "100% natural no artificial additives" and "50% off sale this weekend only" each received an anomaly score of 3 from rule 920220. Under PL1 (T=5), a score of 3 is below the blocking threshold, so the request is allowed through. Under PL2 (T=3), the same score of 3 exactly meets the threshold, so the request is blocked.
Rule 920220 carries the paranoia-level/1 tag. It fired in both configurations. The only thing that changed was T.
At subcategory level, the Special-Chars benign category (the percentage-string group) went from 0.00% FPR under PL1 to 7.04% FPR under PL2. The SQL-Keyword and Scripting-Keyword subcategories were identical across both configurations: their false positive scores already met the PL1 threshold, so the threshold reduction made no difference there. The Neutral subcategory (clean product descriptions) produced 0% FPR in both configurations.
Latency and Resource Usage
H3 predicted PL2 would be slower due to evaluating more rules. It was slightly faster: PL1 averaged 46.66ms versus PL2's 41.93ms. The overlapping standard deviations (~19ms in both) make this directional difference meaningless. No significant CPU or memory difference was observed either.
The likely explanation is that CRS rule evaluation is fast relative to other pipeline overhead, and at the sequential single-threaded traffic volume tested, the marginal cost of loading additional PL2 rules wasn't measurable.
What This Means in Practice
Decoupling threshold from paranoia level. The CRS documentation presents paranoia levels as bundled packages: raise the level, get more rules and a lower threshold together. This study shows those two levers can be operationally separated. If you want PL2-equivalent sensitivity to low-scoring anomalies, you can lower ANOMALY_INBOUND from 5 to 3 within a PL1 configuration. You'd achieve the same blocking behaviour on score-3 requests without loading PL2-specific rules, and without inheriting whatever false positive surface those rules introduce against your specific traffic profile.
Rule exclusions over blanket escalation. The entire FPR increase from PL1 to PL2 in this experiment is traceable to a single rule on a single score value. A targeted exclusion for rule 920220 on percentage-character content would eliminate all five additional false positives without any detection cost. That's a more surgical approach than accepting a higher paranoia level globally and then trying to tune back the noise.
Bypasses require more than threshold changes. The six evading payloads are completely unaffected by threshold manipulation. Three of the four evasion categories (comment manipulation, structural gaps, double encoding) are signature gaps or normalisation limitations. Raising the paranoia level to PL3 or PL4 cannot address them. Double encoding in particular is architectural: it requires recursive normalisation, not tighter thresholds.
Limitations
A few honest caveats worth flagging:
The payload set came from publicly documented sources. This means it likely represents a best-case scenario for CRS, since rule authors have access to the same repositories. Novel or custom-crafted payloads would probably fare at least as well.
The test covered a single endpoint (the Juice Shop search API). Results may not generalise to endpoints handling JSON bodies, file uploads, or multi-parameter forms.
All findings are specific to CRS 3.3.8. Some of the identified bypasses may already be addressed in later releases.
PL3 and PL4 were not tested. The threshold-not-rules finding may or may not hold at higher levels. That would require a separate experiment.
Takeaway
Paranoia level configuration should be treated as an empirical decision, not an assumption. In controlled testing against structured attack traffic, raising from PL1 to PL2 imposed a measurable and predictable false positive cost with zero detection benefit. The improvement came from threshold arithmetic, not additional rule logic. And the payloads that evaded detection did so at both levels, because the gaps are in the signatures, not the sensitivity dial.